
CRISP-DM: La guía definitiva para maximizar el valor de tus datos
¿Te gustaría pasar de la teoría a la práctica en proyectos de analítica? CRISP-DM te aporta un mapa claro para unir negocio y tecnología, evitando decisiones improvisadas.

Si estás recibiendo este correo por primera vez es que te has inscripto directo, te ha referenciado un amigo, o producto de la sincronización automática de mis listas de contactos, Linkedin y otras redes sociales, en caso que no te interese estos contenidos puedes desuscribirte con la opción que figura debajo en este newsletter.🔥 Te pido que compartas esta guía completa de CRISP-DM con tu comunidad. 🔥 Es una guia extensa , con videos y referencias bibliográficas que convendrá leerlo completo desde este enlace “CRISP-DM: La guía definitiva para maximizar el valor de tus datos”🔥 ¿Me ayudas a difundir este contenido? ¿Cuento contigo?
¿Te has preguntado alguna vez cómo estructurar de manera eficiente un proyecto de análisis de datos, evitando pasos confusos y maximizando la alineación con el negocio?
El modelo CRISP-DM (Cross-Industry Standard Process for Data Mining) se ha convertido en el estándar dorado para guiar proyectos de ciencia de datos de principio a fin, ofreciendo un marco confiable y probado en múltiples industrias. Desde entender las motivaciones estratégicas de tu empresa hasta asegurar un despliegue exitoso de modelos en producción, CRISP-DM te ayuda a navegar cada etapa sin perder el rumbo.
Este método no solo se centra en las variables y algoritmos, sino que también prioriza la comprensión del negocio, la calidad de la información y la rentabilidad de la solución.
Es una ruta clara para evitar los clásicos errores en proyectos de análisis: falta de objetivos definidos, datos poco fiables, o dificultades para adoptar la solución en la operación diaria. Al basarse en ciclos iterativos, CRISP-DM te permite refinar y mejorar tus modelos de manera ágil, asegurando que cada nueva versión aporte más valor que la anterior.
En las próximas secciones, descubrirás cómo aplicar este modelo paso a paso, con ejemplos reales, recomendaciones de herramientas y checklists específicos para cada fase. La idea es que te lleves un plan de acción práctico, listo para aplicar en cualquier proyecto de datos que busque resultados concretos.
💡 Si estás listo para dar un salto cualitativo en tus iniciativas de analítica y machine learning, sigue leyendo: la transformación empieza aquí.
CONTENIDO
- Introducción: 1.1. Orígenes e importancia de CRISP-DM: 1.2. Objetivos y alcance de la guía; 1.3. Comparación con otros marcos de trabajo; 1.4. Estructura de la guía.
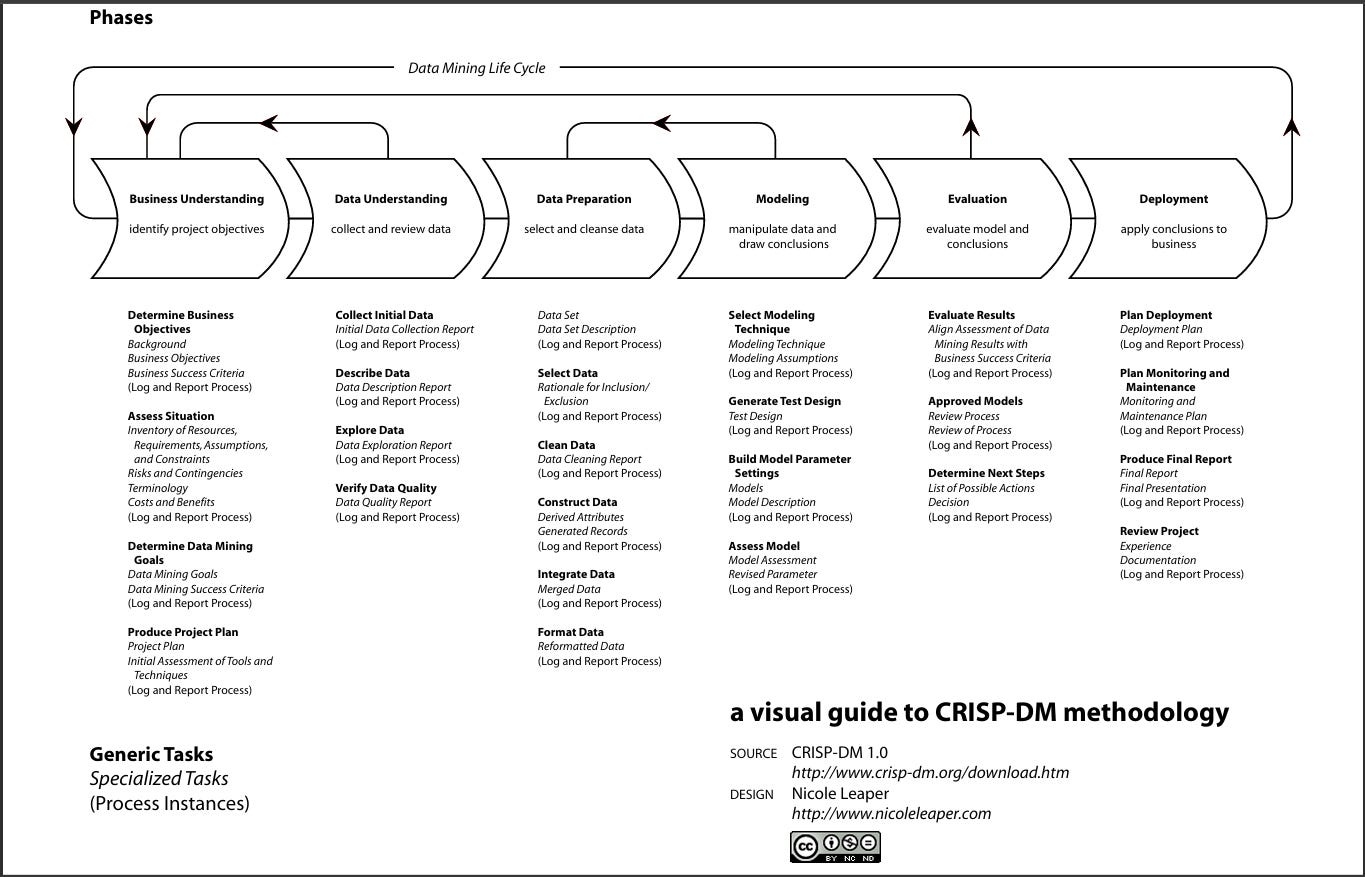
- Fases del modelo CRISP-DM: 2.1. Comprensión del Negocio; 2.2. Comprensión de los Datos; 2.3. Preparación de los Datos; 2.4. Modelado; 2.5. Evaluación; 2.6. Despliegue.
- Aplicaciones Prácticas y Casos de Uso3.1. Sectores e industrias (finanzas, salud, retail, manufactura, etc.)3.2. Herramientas y tecnologías recomendadas3.3. Ejemplos detallados de proyectos concretos.
- Retos y Mejores Prácticas4.1. Principales desafíos en la implementación4.2. Factores de éxito y estrategias recomendadas4.3. Ética y sesgos en la minería de datos
- Conclusiones y Recursos Adicionales5.1. Resumen de los beneficios de CRISP-DM5.2. Fuentes de información, lecturas recomendadas y cursos5.3. Siguientes pasos y proyección a futuro

INTRODUCCIÓN
1.1. Orígenes e importancia de CRISP-DM
El modelo CRISP-DM fue desarrollado a finales de la década de 1990, en un esfuerzo conjunto de varias organizaciones, entre ellas IBM, Daimler Chrysler y NCR.
El objetivo principal era establecer un marco estándar para la ejecución de proyectos de minería de datos, basado en las mejores prácticas de distintos sectores.
Influencia en la industria:
Actualmente, CRISP-DM es uno de los métodos más reconocidos y utilizados en la industria para estructurar proyectos de ciencia de datos y analítica avanzada.
Se estima (según KDnuggets, 2021) que más del 40% de las empresas que trabajan con analítica de datos siguen un proceso muy similar a CRISP-DM, adaptándolo a sus necesidades.
Ventajas clave:
Estandarización: Proporciona un lenguaje común entre distintos equipos (negocio y tecnología), reduciendo la brecha de comunicación.
Reducción de riesgos: Al guiar cada fase de un proyecto, evita omisiones, reduce la probabilidad de errores y facilita la toma de decisiones basadas en datos.
Adaptabilidad: Aunque nació para la “minería de datos” clásica, se aplica perfectamente a proyectos de machine learning, deep learning e incluso analítica en Big Data.
💡 Ejemplo práctico: Una empresa de telecomunicaciones implementa un proyecto de detección de deserción de clientes (churn). Antes de CRISP-DM, sus proyectos se realizaban sin una metodología clara, lo que provocaba retrasos y confusión. Tras adoptar CRISP-DM, el equipo logró definir claramente los objetivos (reducir un 5% la tasa de churn), entender a profundidad las fuentes de datos (datos de facturación, uso de servicio, llamados al call center), preparar las variables adecuadas (numero de quejas, meses de antigüedad), probar diferentes modelos (árboles de decisión, regresión logística) y finalmente desplegar el mejor modelo dentro de sus sistemas de CRM.

1.2. Objetivos y alcance de la guía
Presentar un recorrido detallado de todas las fases de CRISP-DM, brindando recomendaciones prácticas, herramientas y ejemplos concretos que faciliten su adopción en proyectos de minería de datos, analítica avanzada y machine learning.
Alcance:
Se abordan las seis fases clásicas de CRISP-DM.
Se incluyen checklists, mejores prácticas y casos de uso para cada fase.
No se cubren en profundidad los algoritmos de modelado específicos (p.e., redes neuronales, árboles de decisión), pero sí se dan referencias y pautas para su correcta elección e implementación.
💡 Ejemplo de aplicación: Un lector que trabaja en el área de marketing digital de un e-commerce podrá usar la guía para estructurar un proyecto de recomendación de productos, comprendiendo cómo plantear los objetivos de negocio, manejar múltiples fuentes de datos (ventas históricas, comportamiento de navegación, etc.), preprocesarlos adecuadamente, entrenar un modelo y finalmente medir y desplegar los resultados en la plataforma.
1.3. Comparación con otros marcos de trabajo
Existen otros modelos similares a CRISP-DM que han emergido con el auge de la ciencia de datos. Aun así, el grueso de la comunidad sigue prefiriendo CRISP-DM por su flexibilidad y solidez:
SEMMA (Sample, Explore, Modify, Model, Assess): Propuesto por SAS Institute, está más orientado a la herramienta SAS y se centra en el proceso estadístico y no tanto en la comprensión del negocio.
KDD (Knowledge Discovery in Databases): Similar a CRISP-DM, pero CRISP-DM hace más hincapié en la colaboración entre equipos y en la comunicación con el negocio.
TDSP (Team Data Science Process de Microsoft): Propone una estructura de equipo y roles más definidos, pero es relativamente reciente y no está tan ampliamente adoptada.
CRISP-DM sobresale porque pone el foco en el objetivo de negocio desde el primer momento, asegurando que el proyecto de minería de datos responda a necesidades reales y medibles.

1.4. Estructura de la guía
La guía se organiza según las seis fases principales de CRISP-DM:
Comprensión del Negocio
Comprensión de los Datos
Preparación de los Datos
Modelado
Evaluación
Despliegue
Luego, se exploran aplicaciones prácticas, retos frecuentes y buenas prácticas que complementan cada fase, junto con recursos adicionales para profundizar.


FASES DEL MODELO CRISP-DM
El modelo CRISP-DM (Cross-Industry Standard Process for Data Mining) se compone de seis fases que, aunque se describen de forma secuencial, se abordan de manera iterativa y cíclica. Esto significa que en cualquier punto podemos volver a una fase anterior para refinar el trabajo ya realizado.
A continuación, desarrollaremos cada fase con detalles exhaustivos, ejemplos prácticos, checklists y herramientas útiles.

2.1. Comprensión del Negocio (Business Understanding)
Esta es la fase más estratégica y, a menudo, la más subestimada. Aquí se establecen las bases del proyecto, asegurando que la iniciativa de minería de datos responda a necesidades reales de la organización.
Objetivo: Alinear el proyecto con la necesidad real de la organización, definiendo claramente qué se quiere lograr y por qué.
Planteamiento del problema:
Identificar la situación o reto que se pretende resolver (churn de clientes, detección de fraude, segmentación de mercado, etc.).
Delimitar objetivos específicos y medir el valor potencial que aportará la solución.
Determinación del alcance y KPIs:
Establecer indicadores cuantificables que permitan evaluar el éxito (por ejemplo, reducir el churn en un 10%).
Revisar restricciones de tiempo, presupuesto, recursos humanos y regulaciones.
Análisis de riesgos y stakeholders:
Mapear quiénes intervienen (áreas de negocio, TI, clientes, proveedores, reguladores).
Identificar posibles barreras (culturales, técnicas o legales) que puedan frenar o complicar la implementación.
Resultado esperado: Documento o brief que clarifique el propósito de la iniciativa, los criterios de éxito y las implicaciones de negocio.
Preguntas Clave: ¿Cuáles son los principales problemas u oportunidades que queremos abordar? ¿Cuáles son las métricas clave de éxito? ¿Cómo impactarán los resultados esperados en el negocio? ¿Qué restricciones debemos considerar durante el análisis?
💡 Ejemplo de Aplicación: Imaginemos una empresa de seguros que desea reducir el riesgo de fraude en sus operaciones. En esta fase, se identificarían los objetivos de negocio, como reducir las pérdidas financieras debidas a reclamaciones fraudulentas y mejorar la precisión en la detección de fraude. Se formularían preguntas clave sobre cómo se manifiesta el fraude y qué patrones pueden estar asociados con reclamaciones sospechosas.

2.1.1. Objetivos y Alcance
Definir el problema: Determinar con claridad qué se desea resolver o mejorar (p.ej. reducir la tasa de deserción de clientes, optimizar la asignación de recursos).
Fijar métricas de éxito: Por ejemplo, reducir el churn en un 10%, aumentar ventas en un 15% o mejorar la precisión de un modelo en un 5%.
Acotar el alcance: Identificar qué áreas de negocio participan, qué procesos se verán impactados y qué recursos (humanos, tecnológicos, presupuestales) se requieren.
💡 Ejemplo práctico: Una compañía de seguros busca optimizar su póliza para jóvenes conductores. El objetivo de negocio es disminuir la siniestralidad de ese segmento en un 8% anual, lo que implica identificar variables asociadas a la conducción de riesgo.
2.1.2. Análisis de la Situación Actual
Revisión de procesos existentes: ¿Cómo se gestiona actualmente el problema? ¿Existe un sistema de alertas o un CRM que registre todos los datos?
Evaluación de oportunidades y limitaciones: ¿Hay restricciones legales o regulatorias? ¿Se cuenta con el presupuesto suficiente?
Variación de ejemplo:
Sector bancario: Respetar normativas de protección de datos al tratar información financiera sensible.
Sector salud: Cumplir con leyes de privacidad de datos de pacientes (p.ej. HIPAA en EE.UU.).
2.1.3. Identificación de Stakeholders
Stakeholders de negocio: Directores, gerentes y usuarios finales del análisis.
Stakeholders técnicos: Científicos de datos, ingenieros de datos, equipo de IT.
Otros interesados: Reguladores, socios, clientes.
2.1.4. Checklist
Definición clara de objetivos de negocio
¿Qué problema se quiere resolver?
¿Cuáles son los KPIs o métricas que medirán el éxito?
Alcance y restricciones
¿Se han identificado limitaciones de tiempo, presupuesto o recursos?
¿Existen regulaciones o normativas que cumplir (p. ej. GDPR, leyes locales)?
Alineación con stakeholders
¿Quiénes son los involucrados (directivos, usuarios finales, equipo de TI, etc.)?
¿Están de acuerdo en la definición de objetivos y prioridades?
Análisis de riesgos
¿Cuáles son los principales riesgos (falta de datos, resistencia cultural, etc.)?
¿Cómo se mitigarán?
2.1.5. Herramientas Útiles
Reuniones y talleres con el negocio: Miro, Lucidchart o Microsoft Whiteboard para mapear procesos y requisitos.
Gestión de proyectos: Asana, Trello, Jira para asignar tareas y hacer seguimiento.
Documentación y colaboración: Notion, Confluence, Google Docs para recolectar y centralizar la información.


2.2. Comprensión de los Datos (Data Understanding)
Una vez establecidos los objetivos de negocio, es momento de examinar los datos disponibles y su relevancia para el problema.
Objetivo: Conocer las fuentes de datos disponibles, evaluando su calidad, fiabilidad y relevancia para cumplir con los objetivos del negocio.
Recolección inicial de datos:
Inventario de fuentes (internas y externas): sistemas CRM, ERP, bases públicas, APIs, etc.
Verificar accesibilidad y formato (estructurado, semiestructurado o no estructurado).
Exploración y análisis preliminar (EDA):
Aplicar estadística descriptiva y visualizaciones para detectar patrones, outliers y relaciones entre variables.
Evaluar si los datos son suficientes para abordar el problema o se requieren fuentes adicionales.
Revisión de calidad:
Identificar valores nulos, duplicados o inconsistentes.
Cuantificar el nivel de confiabilidad de los datos y estimar el esfuerzo necesario para corregir problemas.
Resultado esperado: Un diagnóstico de los datos existentes, con hallazgos clave sobre su integridad y pertinencia para los objetivos planteados.
💡 Ejemplo de Aplicación: En el caso de la empresa de seguros, se recopilarían datos históricos de reclamaciones, como fechas, tipos de siniestros, datos del cliente, entre otros. Se exploraría la calidad de los datos para identificar anomalías o datos faltantes que pudieran afectar la precisión del análisis de fraude.
2.2.1. Identificación y Recolección de Datos
Fuentes Internas: Bases de datos transaccionales (ERP, CRM), registros de ventas, logs de aplicaciones, etc.
Fuentes Externas: Datos públicos (INE, World Bank), redes sociales, APIs de terceros, etc.
💡 Ejemplo práctico: En la compañía de seguros que busca reducir siniestralidad, se recopilan datos de pólizas anteriores, historial de accidentes, demográficos y hábitos de conducción de los clientes.
2.2.2. Exploración de Datos (EDA)
Análisis Descriptivo: Estadísticas básicas (media, mediana, moda), visualización de la distribución de variables.
Detección de outliers: Valores atípicos que pueden distorsionar el análisis.
Relaciones entre variables: Análisis de correlaciones, tabulaciones cruzadas.
💡 Variación de ejemplo: Retail: Analizar la correlación entre el horario de compra y las promociones aplicadas. Fintech: Detectar patrones de fraude con análisis exploratorio de transacciones.
2.2.3. Evaluación de la Calidad de los Datos
Valores nulos o faltantes: ¿Son datos perdidos o no aplican al caso?
Datos inconsistentes: ¿Existen registros duplicados o con formatos erróneos?
Rango y validez: Asegurarse de que los valores estén dentro de umbrales lógicos.
2.2.4. Checklist
Inventario de fuentes de datos
¿Qué bases de datos internas y externas se utilizarán?
¿Los datos están disponibles y son accesibles?
Evaluación de la calidad de datos
¿Existen valores nulos, duplicados o inconsistencias?
¿Hay variables irrelevantes o con valores fuera de rango?
Análisis exploratorio (EDA)
¿Se han identificado correlaciones básicas o distribuciones importantes?
¿Hay outliers que puedan distorsionar el análisis?
Documentación de hallazgos
¿Se registra la calidad, los problemas detectados y las potenciales soluciones?
2.2.5. Herramientas Útiles
Python (pandas, NumPy, matplotlib, seaborn) o R (tidyverse, ggplot2) para análisis exploratorio.
Tableau, Power BI para visualizaciones rápidas y dashboards.
SQL (MySQL, PostgreSQL) y/o NoSQL (MongoDB, Cassandra) según la estructura y el volumen de datos.


2.3. Preparación de los Datos (Data Preparation)
Aquí se realiza la limpieza, transformación y enriquecimiento de los datos para que estén listos para el modelado.
Objetivo: Transformar, limpiar e integrar los datos para que sean utilizables en la fase de modelado con la mayor calidad y coherencia posible.
Limpieza y normalización:
Eliminar duplicados, corregir formatos (fechas, tipos de dato), manejar valores nulos (imputación o eliminación).
Unificar criterios de codificación, nombres de campos y escalas.
Selección de variables y creación de nuevas (Feature Engineering):
Escoger los atributos más relevantes, según la comprensión de negocio y la exploración de datos.
Generar variables derivadas (combinaciones, agregaciones, transformaciones) que aporten valor predictivo.
Enriquecimiento y consolidación:
Integrar distintas tablas o fuentes mediante joins y llaves comunes.
Verificar la consistencia final, garantizando un dataset “limpio” y con todas las variables requeridas.
Resultado esperado: Un conjunto de datos (dataset) listo para el entrenamiento del modelo, documentando cada paso de limpieza y transformación.
💡 Ejemplo de Aplicación: En la empresa de seguros, se podría eliminar información redundante, imputar valores faltantes y crear nuevas variables que puedan ayudar a identificar patrones sospechosos de fraude, como la frecuencia de reclamaciones por parte de un cliente en un corto periodo de tiempo.
2.3.1. Limpieza y Formateo
Remoción de duplicados: Usualmente detectados con un ID único.
Corrección de formatos: Transformar fechas, convertir texto a minúsculas, unificar codificaciones.
Imputación de valores faltantes: Métodos estadísticos (media, mediana), algoritmos de imputación (KNN Imputer) o eliminación de registros, según sea apropiado.
2.3.2. Selección y Creación de Variables (Feature Engineering)
Selección de atributos relevantes: Con base en la exploración previa y el conocimiento del negocio.
Transformaciones avanzadas: Escalado, normalización, binning de variables continuas.
Features derivadas: Ratios, interacciones entre variables (p.ej. multiplicación de variables, creación de indicadores).
💡 Ejemplo práctico: En la compañía de seguros, se crea una variable compuesta “índice de riesgo” basado en la combinación de la edad del conductor, historial de reclamos y tiempo en la aseguradora.
2.3.3. Consolidación y Formato Final
Integración de múltiples fuentes: Unir dataframes/tablas (join) para consolidar la información en un único dataset.
Validación del dataset final: ¿Cada fila representa un caso único? ¿Se mantiene la coherencia interna?
2.3.4. Checklist
Limpieza y formateo
¿Se han eliminado duplicados y valores atípicos o nulos no manejables?
¿Se han unificado formatos (fechas, tipos de datos)?
Selección de variables
¿Cuáles son las columnas relevantes para el modelo?
¿Qué criterios se utilizaron para descartar variables?
Feature engineering
¿Se han creado nuevas variables derivadas (interacciones, transformaciones)?
¿Se han aplicado técnicas de escalado (normalización, estandarización) cuando procede?
Integración de datos
¿Se han combinado correctamente las fuentes en un único dataset (joins, merges)?
¿Se mantiene la coherencia e integridad tras la unión?
2.3.5. Herramientas Útiles
Scikit-learn (ColumnTransformer, SimpleImputer, StandardScaler) para preprocesamiento en Python.
PySpark para transformaciones en entornos de big data.
Airflow, Luigi para orquestar pipelines de preparación de datos a gran escala.


2.4. Modelado (Modeling)
En esta fase se escogen los algoritmos de modelado, se ajustan los parámetros y se itera para encontrar la mejor solución analítica.
Objetivo: Seleccionar y entrenar algoritmos que resuelvan la tarea planteada (clasificación, regresión, clustering, etc.), ajustando parámetros para optimizar el rendimiento.
Selección de técnicas y algoritmos:
Determinar si se trata de un problema supervisado (clasificación, regresión) o no supervisado (clustering, reglas de asociación).
Escoger modelos iniciales (por ejemplo, árboles de decisión, regresión logística, métodos de ensamble) para realizar pruebas comparativas.
División del dataset y entrenamiento:
Separar el dataset en entrenamiento y test (y eventualmente validación).
Entrenar el modelo ajustando hiperparámetros (Grid Search, Random Search, Bayesian Optimization).
Evaluación interna y comparación de modelos:
Medir métricas relevantes (precisión, recall, F1, RMSE, AUC-ROC, etc.) según el tipo de problema.
Escoger el modelo o conjunto de modelos con mejor equilibrio entre desempeño y complejidad.
Resultado esperado: Prototipo(s) de modelo con parámetros ajustados, junto con una justificación basada en métricas de desempeño y necesidades de negocio.
💡 Ejemplo de Aplicación: Se podría aplicar un modelo de clasificación para predecir la probabilidad de fraude en una reclamación. Técnicas como árboles de decisión o redes neuronales se utilizarían para identificar características clave que separan las reclamaciones fraudulentas de las legítimas.
2.4.1. Selección de Algoritmos
Modelos supervisados (regresión, clasificación) o no supervisados (clustering, reducción de dimensionalidad), dependiendo del objetivo.
Consideraciones: Volumen de datos, complejidad, interpretabilidad, velocidad de predicción.
💡 Variación de ejemplo:
Clasificación (banco): Predecir si un cliente es propenso a fraude o no.
Regresión (retail): Prever ventas futuras o demanda de un producto.
Clustering (marketing): Segmentar clientes según patrones de compra.
2.4.2. Entrenamiento y Validación de Modelos
División del dataset: Separa los datos en entrenamiento, validación y test (típicamente 70%-15%-15% o similar).
Cross-Validation: K-fold cross-validation para asegurar robustez y evitar overfitting.
Optimización de hiperparámetros: Uso de Random Search, Grid Search o Bayesian Optimization.
2.4.3. Selección del Modelo Óptimo
Métricas: Accuracy, F1-score, Recall, Precision, RMSE, AUC-ROC, etc., según el tipo de problema.
Interpretabilidad: Para negocio, a veces es preferible un modelo un poco menos preciso pero más explicable (p.ej. árboles de decisión vs. redes neuronales).
2.4.4. Checklist
Selección de algoritmos
¿Se trata de un problema de clasificación, regresión o clustering?
¿Existen modelos de baseline (reglas manuales o modelado simple) para comparar?
Entrenamiento y validación
¿Se dividió correctamente el dataset en train/test o se aplicó k-fold cross-validation?
¿Se ajustaron los hiperparámetros (grid search, random search, bayesiano)?
Métricas de desempeño
¿Se definieron métricas acordes al objetivo (accuracy, F1, AUC-ROC, RMSE, etc.)?
¿Se comparan varios modelos bajo las mismas condiciones?
Interpretabilidad
¿Se necesita explicar las predicciones a nivel de negocio (SHAP, LIME, árboles de decisión)?
¿Se documentan los supuestos y limitaciones de cada modelo?
2.4.5. Herramientas Útiles
Python: scikit-learn, XGBoost, LightGBM, PyTorch, TensorFlow.
R: Caret, mlr3, h2o.
MLflow, Weights & Biases para seguimiento de experimentos y versionado de modelos.


2.5. Evaluación (Evaluation)
Una vez que se tiene un modelo o conjunto de modelos candidatos, se valida su desempeño y se revisa si responde al objetivo de negocio.
Objetivo: Validar que el modelo cumple con los criterios de éxito definidos en la fase de negocio y que se comporta adecuadamente en datos no vistos.
Pruebas finales y validación externa:
Evaluar el modelo en datos de prueba no usados en el entrenamiento.
Considerar también data de entornos reales o pilotos (si están disponibles).
Revisión con stakeholders y viabilidad de implementación:
Confirmar si los resultados son interpretables y alineados con los objetivos (por ejemplo, reducción del churn o precisión en la detección de fraude).
Ajustar el umbral de decisión o realizar mejoras finales en el modelo si no se alcanzan las métricas esperadas.
Detección de sesgos y consideraciones éticas:
Revisar posibles disparidades de desempeño entre subgrupos (edad, género, región).
Asegurar cumplimiento de normativas (GDPR, CCPA, etc.) y prácticas de IA responsable.
Resultado esperado: Un modelo avalado a nivel técnico (métricas) y de negocio (objetivos, ROI, ética). Si no cumple, se retroalimenta y se vuelve a fases previas (iteración).
💡 Ejemplo de Aplicación: Para la empresa de seguros, se evaluaría la precisión del modelo en la detección de fraude. Si el modelo presenta una tasa alta de falsos positivos (reclamaciones legítimas clasificadas como fraudulentas), sería necesario ajustar los parámetros del modelo o volver a la fase de preparación de datos.
2.5.1. Revisión de Resultados Técnicos
Métricas de evaluación: Dependen del problema; p.ej. MAE, MSE, RMSE para regresión, Precisión, Recall, F1, AUC-ROC para clasificación.
Detección de overfitting: ¿El modelo funciona bien en entrenamiento pero mal en test?
2.5.2. Relevancia para el Negocio
Retorno de Inversión (ROI): Proyectar beneficios vs. costos de implementación.
Interpretación: Si el modelo indica que cierto perfil de cliente es riesgoso, ¿se entiende por qué?
Impacto colateral: ¿Genera un sesgo negativo hacia un grupo de clientes? ¿Afecta la reputación de la empresa?
💡 Ejemplo práctico: La compañía de seguros realiza una prueba piloto con clientes reales y monitorea la reducción de accidentes en el segmento joven. Observan que el modelo reduce siniestralidad en un 5% (el objetivo era 8%). Deciden reevaluar el feature engineering y probar un algoritmo adicional.
2.5.3. Ajustes Finales y Aprobación
Retroalimentación con stakeholders: Presentar resultados y escenarios de implementación.
Selección final del modelo para su despliegue.
Planes de mejora continua: Reservar un procedimiento para actualizar el modelo periódicamente.
2.5.4. Checklist
Validación final en datos de test o en piloto
¿El modelo mantiene un desempeño estable en datos nunca vistos?
¿Se ha realizado un test A/B o un piloto controlado para validar la utilidad de negocio?
Concordancia con objetivos de negocio
¿El desempeño técnico (p. ej. 92% de precisión) se traduce en beneficios tangibles?
¿Se ha calculado el ROI potencial?
Revisión de sesgos y ética
¿Existen disparidades de desempeño en distintos subgrupos (edad, género, localidad)?
¿Se cumple la normativa de privacidad y protección de datos (GDPR, CCPA)?
Retroalimentación y mejoras
¿En caso de no cumplir las metas, se regresa a fases previas (data prep, modelado) para refinar?
2.5.5. Herramientas Útiles
SHAP, LIME para explicar modelos complejos y detectar sesgos.
TensorBoard, MLflow para comparar métricas de modelos a lo largo del tiempo.
Tableau, Power BI para presentar resultados a los stakeholders de manera accesible.


2.6. Despliegue (Deployment)
Finalmente, se pone el modelo en producción o en el entorno en el que generará valor de negocio.
Objetivo: Integrar el modelo en un entorno productivo o en los procesos de la organización, garantizando su correcto uso y mantenimiento.
Implementación en producción:
Exponer el modelo como un servicio (API REST, microservicios) o integrarlo en sistemas existentes (CRM, ERP, apps web).
Contenerización y orquestación (Docker, Kubernetes) para garantizar escalabilidad y disponibilidad.
Monitoreo y mantenimiento continuo:
Medir el desempeño real del modelo (tasa de aciertos, costos, beneficios).
Configurar alertas que detecten caídas de rendimiento (data drift, concept drift).
Ciclo de retroalimentación:
Actualizar o reentrenar el modelo de forma periódica con datos nuevos.
Documentar cambios y publicar mejoras progresivas (versionado de modelos).
Resultado esperado: El modelo o solución analítica funcionando de manera estable, generando valor tangible y con un plan definido de seguimiento y soporte.
💡 Ejemplo de Aplicación: En la empresa de seguros, el modelo de detección de fraude se implementaría en el sistema de gestión de reclamaciones. Los analistas recibirían alertas automáticas cuando una reclamación sea clasificada como potencialmente fraudulenta, lo cual permitiría una revisión adicional antes de aprobar el pago
2.6.1. Integración con Sistemas Operativos
API o microservicios: Para exponer el modelo a aplicaciones internas o externas.
Automatización de pipeline: Asegurar actualizaciones periódicas y reentrenamiento.
💡 Variación de ejemplo: E-commerce: Se integra un modelo de recomendación vía API REST para personalizar la página de inicio del cliente. Banca: El modelo de riesgo crediticio se despliega en el core bancario, evaluando solicitudes de préstamos en tiempo real.
2.6.2. Monitoreo y Mantenimiento
Seguimiento de métricas: Asegurarse de que el modelo mantiene un desempeño estable (drift de datos).
Alertas tempranas: Detectar caídas bruscas de rendimiento o cambios en la distribución de datos.
2.6.3. Feedback y Actualización
Re-entrenamiento: Programar ciclos de actualización (p.ej. mensual, trimestral) basados en nuevos datos.
Feedback de usuarios: Incorporar retroalimentación de clientes y áreas de negocio para mejorar.
2.6.4. Checklist
Implementación en producción
¿El modelo está listo como microservicio (API REST, contenedor Docker, etc.)?
¿Se han considerado requerimientos de escalabilidad y latencia (Kubernetes, AWS, Azure, GCP)?
Monitoreo continuo
¿Se definen métricas clave para detectar data drift o concept drift?
¿Quién se encarga de supervisar y mantener los modelos en producción?
Plan de mantenimiento y actualización
¿Cada cuánto se reentrena el modelo con datos recientes?
¿Se tiene un procedimiento de rollback en caso de fallos?
Documentación y comunicación
¿Se documenta el pipeline de despliegue y la configuración del entorno productivo?
¿Los stakeholders clave (equipo de negocio, equipo técnico) reciben reportes de rendimiento del modelo?
2.6.5. Herramientas Útiles
Docker, Kubernetes para contenerización y orquestación en la nube o en servidores on-premise.
Airflow, Prefect, Luigi para orquestación de pipelines de datos y reentrenamiento.
Herramientas de MLOps: MLflow (gestión de modelos), Seldon Core (despliegue de modelos), Kubeflow (pipelines end-to-end).
Importancia del enfoque iterativo
Aunque se describan en orden, estas fases no siempre se ejecutan de manera lineal. Es común volver atrás (por ejemplo, a la preparación de datos) para ajustar variables tras ver resultados de modelado o, incluso, reformular los objetivos del negocio si los hallazgos difieren de las expectativas iniciales.
Retroalimentación constante: El aprendizaje incremental permite optimizar los resultados y corregir rumbos a tiempo.
Refinamiento gradual: Cada iteración mejora la calidad de los datos, la selección de variables y el ajuste del modelo.
Mayor robustez: Mediante la iteración, se consolidan análisis más sólidos, reduciendo riesgos y evitando sorpresas en la fase de despliegue.
Estas seis fases forman un ciclo iterativo que asegura una visión integral y alineada con el negocio, desde el planteamiento del problema hasta la adopción final de la solución. La clave está en documentar cada paso, involucrar a los stakeholders pertinentes y buscar siempre la mejora continua.

APLICACIONES PRÁCTICAS Y CASOS DE USO
En esta sección, examinaremos cómo se aplica CRISP-DM en diferentes sectores e industrias, las herramientas y tecnologías más habituales y algunos ejemplos detallados de proyectos. Esto te ayudará a entender la versatilidad de este modelo y cómo adaptarlo según el contexto de cada organización.
3.1. Sectores e Industrias
La metodología CRISP-DM se ha utilizado en numerosos proyectos de analítica avanzada, machine learning y minería de datos en todo tipo de sectores:
3.1.1. Finanzas y Banca
Detección de fraude: Uso de algoritmos de clasificación supervisada para identificar transacciones sospechosas.
Modelado de riesgo crediticio: Evaluación del perfil de clientes para aprobar préstamos.
Guía estructurada para cumplir regulaciones y procesos de auditoría.
Asegura validación de modelos (fase de Evaluación) con métricas financieras relevantes.
💡 Caso real conocido: JPMorgan Chase usa metodologías similares a CRISP-DM para sus proyectos de Anti-Money Laundering (AML). Tienen que integrar múltiples fuentes de datos (transacciones globales, listas negras) y asegurarse de cumplir normas (FATF, OFAC).
3.1.2. Retail y E-Commerce
Análisis de Canasta de Compras (Market Basket Analysis) para identificar productos que se suelen vender en conjunto.
Sistemas de Recomendación (collaborative filtering, content-based).
Permite iterar con distintas fuentes de datos (historial de compra, datos de navegación) y obtener resultados rápidos, alineando el objetivo de negocio (más ventas) con métricas de calidad (precisión de recomendación).
💡 Caso práctico: Amazon y Mercado Libre usan metodologías inspiradas en CRISP-DM para diseñar y ajustar sus sistemas de recomendación, integrando big data y analizando miles de millones de transacciones.
3.1.3. Salud (Healthcare)
Diagnóstico predictivo de enfermedades crónicas (diabetes, hipertensión) a partir de datos clínicos.
Optimización de recursos hospitalarios (p.ej. camas de UCI).
Asegura un proceso de validación riguroso, crucial cuando se manejan datos sensibles.
Define un marco que involucra desde la comprensión del negocio (directrices médicas) hasta la evaluación (seguridad del paciente).
💡 Caso de uso: Hospitales de EE.UU. han aplicado CRISP-DM para proyectos de predicción de readmisiones. Integran historial médico, prescripciones y factores socioeconómicos en un modelo que reduce costos y mejora la atención.
3.1.4. Manufactura e Industria 4.0
Mantenimiento predictivo: Prever fallas en maquinaria basándose en sensores IoT.
Optimización de la línea de producción (reducción de tiempo de inactividad, mejora de calidad).
La fase de Comprensión de Datos se vuelve crítica cuando hay volúmenes masivos de datos de sensores.
El ciclo de Despliegue requiere integrar modelos en sistemas de control industrial (SCADA, PLC).
💡 Caso práctico: Bosch (fabricante de componentes automotrices) adoptó CRISP-DM para su “Industry 4.0 lab”. Proyectos de análisis de vibraciones y temperatura en líneas de montaje.
3.1.5. Marketing y Publicidad
Segmentación de clientes (clustering) para campañas personalizadas.
Optimización de canales de marketing con atribución multi-touch.
El objetivo de negocio (más conversiones, menos costo por adquisición) define qué variables o características se necesitan (historial de clics, preferencia de canales).
💡 Caso práctico: Procter & Gamble utiliza modelos predictivos para enfocarse en audiencias específicas y optimizar presupuestos de publicidad en medios digitales.

3.2. Herramientas y Tecnologías Recomendadas
Dependiendo del tamaño y la complejidad del proyecto, existen diferentes tecnologías que ayudan a implementar CRISP-DM de forma eficiente:
3.2.1. Herramientas para Exploración de Datos y Visualización
Python (pandas, seaborn, matplotlib): Muy popular para EDA y modelado inicial.
R (tidyverse, ggplot2): Comunidad estadística sólida y excelentes capacidades de gráficos.
Tableau, Power BI, QlikView: Plataformas de BI para dashboards interactivos.
3.2.2. Almacenamiento y Procesamiento
Bases de datos relacionales (MySQL, PostgreSQL): Adecuadas para proyectos de tamaño mediano.
Bases de datos NoSQL (MongoDB, Cassandra): Cuando se manejan datos semiestructurados o grandes volúmenes.
Hadoop, Spark: Procesamiento distribuido en entornos de big data (decenas de TB o más).
3.2.3. Orquestación y Gestión de Pipelines
Airflow: Orquestación de flujos de trabajo con programaciones complejas.
Luigi: Enfoque de pipeline modulares.
Prefect: Nueva alternativa con enfoque más “Pythonic” y flexible.
3.2.4. MLOps y Despliegue de Modelos
MLflow, DVC, Kubeflow: Seguimiento y versionado de modelos.
Docker, Kubernetes: Despliegue escalable.
Servicios en la nube: AWS Sagemaker, Azure ML, Google Cloud AI Platform.
Nota: La elección de la herramienta dependerá de factores como el presupuesto, la infraestructura existente, la experiencia del equipo y el volumen de datos.

3.3. Ejemplos Detallados de Proyectos Concretos
A continuación, presentamos dos ejemplos detallados para ilustrar un proyecto de CRISP-DM de principio a fin en distintos contextos.
3.3.1. Ejemplo A: Detección de Fraude en Pagos (Fintech)
Contexto:
Una empresa de pagos electrónicos quiere implementar un sistema de detección de transacciones fraudulentas en tiempo real.
El fraude actual genera pérdidas de unos 3 millones de dólares anuales.
Fase 1: Comprensión del Negocio
Objetivo: Reducir el costo de fraude en un 50% sin aumentar excesivamente la tasa de falsos positivos (rechazar transacciones legítimas).
Stakeholders: Equipo de Riesgo, Data Science, TI, Soporte Legal.
Fase 2: Comprensión de los Datos
Fuentes: Logs de transacciones, datos de usuarios (ubicación, historial de uso), listas negras de tarjetas.
EDA: Se detecta que una proporción menor al 0.5% de las transacciones son fraudulentas (problema de dataset desbalanceado).
Fase 3: Preparación de los Datos
Limpieza: Eliminación de duplicados y corrección de formatos de fecha y hora.
Feature engineering: Cálculo del tiempo medio entre transacciones, país de origen vs. país de uso, frecuencia de devoluciones.
Fase 4: Modelado
Modelos: Random Forest con técnicas de oversampling (SMOTE) para lidiar con el desbalance. XGBoost con parámetros ajustados.
Validación: Utilizan F1-score y AUC-ROC. Se implementa una validación estratificada.
Fase 5: Evaluación
Resultado: XGBoost obtiene AUC-ROC = 0.96, superior al baseline (modelo manual de reglas con AUC-ROC = 0.85).
Check de negocio: Comparan reducción de fraude estimada (70% vs 50% requerido) y tasa de rechazo de transacciones legítimas (se mantiene en 2%, aceptable).
Fase 6: Despliegue
Implementación: El modelo se expone como un microservicio REST en Kubernetes.
Monitoreo: Se controla la tasa de fraude semanalmente y se recibe feedback del equipo de soporte.
Plan de actualización: Re-entrenamiento mensual con datos recientes.
Resultado final: Reducción del fraude en un 65% el primer trimestre. Ahorro directo cercano a 2 millones de dólares en pérdidas potenciales.

3.3.2. Ejemplo B: Segmentación de Clientes para Campañas de Marketing (Retail)
Contexto:
Una cadena de supermercados en línea quiere crear segmentos de clientes para personalizar las campañas publicitarias.
Desean aumentar un 10% las ventas en la categoría de productos frescos y reducir el costo de marketing.
Fase 1: Comprensión del Negocio
Objetivo: Identificar segmentos de clientes con mayor probabilidad de compra de productos frescos.
Stakeholders: Gerencia de Marketing, Departamento de Data Analytics, Proveedores de Productos Frescos.
Fase 2: Comprensión de los Datos
Fuentes: Historial de compras de los últimos 2 años. Datos demográficos (edad, ubicación geográfica). Datos de comportamiento (cuándo abren newsletters, qué productos buscan).
EDA: Se observa que el 30% de clientes compran productos frescos al menos una vez por semana, y ese grupo representa el 50% de la facturación de la categoría.
Fase 3: Preparación de los Datos
Limpieza: Se unifica el formato de direcciones y correos electrónicos.
Feature engineering: Frecuencia de compra semanal, gasto promedio en frescos, ratio de compra online vs. en tienda física, estacionalidad.
Fase 4: Modelado
Algoritmo: Clustering no supervisado con K-means.
Validación: Escoger el número de clusters usando el método del codo (Elbow Method) y el coeficiente de silhouette.
Fase 5: Evaluación
Identificación de segmentos:
Frecuentes Alta Gama: Compran frescos costosos y visitan la tienda online con frecuencia.
Ocasionales Promociones: Compran frescos solo cuando hay ofertas.
Clientes Nuevos: Historial de compra reducido, pero alto engagement en newsletters.
Negocio: Se desarrollan campañas diferenciadas (más agresivas con el segmento “Ocasionales Promociones”, y VIP para “Frecuentes Alta Gama”).
Fase 6: Despliegue
Implementación: Carga diaria de datos en un sistema de CRM que etiqueta automáticamente a los clientes en su segmento.
Monitoreo: Se analiza el impacto de las nuevas campañas en ventas de frescos cada mes.
Resultado final: Aumento del 12% en ventas de productos frescos en tres meses. Segmentos bien identificados que permiten marketing personalizado.

RETOS Y MEJORES PRÁCTICAS
Aunque CRISP-DM proporciona un marco muy sólido para llevar a cabo proyectos de minería de datos y ciencia de datos, la realidad de la implementación puede presentar obstáculos que, de no gestionarse correctamente, podrían poner en riesgo el éxito del proyecto. En esta sección, revisaremos los desafíos más habituales, los factores de éxito y la importancia de la ética y la equidad en el tratamiento de datos.
4.1. Principales Desafíos en la Implementación
4.1.1. Calidad y Disponibilidad de Datos
Problema: Datos incompletos, ruidosos o con múltiples fuentes que no están unificadas.
Consecuencia: Modelos con pobre desempeño y/o con sesgos graves.
Cómo abordarlo: Establecer políticas de Data Governance para estandarizar la captación de datos. Realizar auditorías periódicas de datos (data audits) y usar herramientas de Data Quality (por ejemplo, Great Expectations).
💡 Ejemplo: Una aseguradora descubre que sus registros de clientes tienen formatos dispares (errores en los nombres, direcciones incompletas), lo que dificulta la unificación al iniciar el proyecto de predicción de siniestros.
4.1.2. Falta de Objetivos Claros
Problema: Proyectos iniciados por impulso tecnológico sin una meta de negocio definida.
Consecuencia: Dificultad para justificar la inversión y medir el ROI.
Cómo abordarlo: Hacer hincapié en la fase de Comprensión del Negocio. Definir desde el principio KPIs o métricas de éxito consensuadas.
💡 Ejemplo: Un retailer quiere usar “Big Data” sin definir si el fin es mejorar la retención de clientes, optimizar inventarios o incrementar ventas en línea.
4.1.3. Resistencia al Cambio Cultural
Problema: Equipos de trabajo que temen la automatización, falta de comprensión de la utilidad de los modelos o barreras organizacionales.
Consecuencia: Poco apoyo de la organización, baja adopción de las soluciones analíticas.
Cómo abordarlo: Fomentar la cultura data-driven mediante formaciones internas y la comunicación clara de beneficios. Incluir a los stakeholders desde el principio para que se sientan parte del proceso.
💡 Ejemplo: Un equipo de ventas considera que los modelos de predicción de churn sustituyen su experiencia, generando tensión y poca colaboración en la fase de despliegue.
4.1.4. Escalabilidad y Rendimiento
Problema: Modelos o pipelines que funcionan en entornos de prueba, pero se vuelven lentos o inaccesibles en producción con grandes volúmenes de datos.
Consecuencia: Caídas del sistema, tiempos de respuesta inaceptables, sobrecostos en infraestructura.
Cómo abordarlo: Diseñar la arquitectura de datos con escalabilidad en mente (uso de Spark, Kubernetes, etc.). Realizar pruebas de estrés y dimensionamiento de recursos (load testing).
💡 Ejemplo: Una compañía fintech entrena un modelo de fraude en una muestra de datos. Al escalar a millones de transacciones diarias, el sistema se sobrecarga y demora en responder.
4.1.5. Ciclo de Vida del Modelo
Problema: Tras el despliegue, el modelo se “olvida” y no se monitoriza si sigue funcionando adecuadamente (data drift, concept drift).
Consecuencia: Con el tiempo, el desempeño del modelo decae y las predicciones dejan de ser confiables.
Cómo abordarlo: Implementar un plan de MLOps con monitoreo continuo, alertas y reentrenamiento periódico. Realizar análisis de drift para detectar cambios en la distribución de los datos.
💡 Ejemplo: Una aplicación móvil de recomendaciones de productos observa que, meses después de implementar el modelo, las preferencias de los clientes cambian y las recomendaciones dejan de ser relevantes.

4.2. Factores de Éxito y Estrategias Recomendadas
4.2.1. Alineación entre Negocio y Tecnología
El equipo de Data Science debe trabajar codo a codo con los líderes del negocio para definir objetivos, métricas y prioridades. Buenas prácticas: Reuniones regulares de seguimiento. Un Product Owner o líder de proyecto que hable ambos “idiomas” (negocio y tecnología).
💡 Preguntas Checklist: ¿Tenemos una carta de objetivos y un plan de ejecución común? ¿Existen mecanismos de feedback frecuente (demos, retroalimentación)?
4.2.2. Metodología Ágil
Combinar CRISP-DM con enfoques ágiles (Scrum, Kanban) permite entregar valor en incrementos, reducir riesgos y adaptarse a cambios. Beneficios: Detección temprana de problemas, priorización dinámica de tareas, transparencia.
💡 Preguntas Checklist: Dividir el proyecto en sprints: cada sprint abarca fases pequeñas de data ingestion, EDA o modelado rápido, presentando resultados parciales a los stakeholders.
4.2.3. Documentación y Versionado
Documentar cada fase y versión del modelo, registrar cambios en los datos y las transformaciones realizadas.
4.2.4. Formación y Capacitación Continua
Es fundamental que el equipo y la organización se actualicen en técnicas y herramientas emergentes (AutoML, MLOps, nuevas librerías). Buenas prácticas: Plan de desarrollo de habilidades en ciencia de datos. Participar en comunidades y foros (KDnuggets, Kaggle, Stack Overflow).
4.2.5. Control de Calidad
Implementar tests automatizados para garantizar la consistencia de los datos y la fiabilidad del pipeline. Buenas prácticas: Test unitarios en scripts de limpieza. Validaciones de esquema en bases de datos (p.ej. con Great Expectations).

4.3. Ética y Sesgos en la Minería de Datos
Uno de los puntos más delicados en la industria de la ciencia de datos es la ética y la equidad en el tratamiento de la información y en las decisiones automatizadas.
4.3.1. Sesgos en los Datos
Tipo de sesgo: Muestra no representativa: Se entrena un modelo con datos de un segmento poblacional reducido, lo que afecta la generalización. Variables sensibles: Edad, género, raza, etc. que pueden introducir discriminación.
Impacto: El modelo perpetúa o agrava desigualdades.
Buenas prácticas: Eliminar o reducir la importancia de variables sensibles (si no son estrictamente necesarias). Auditar periódicamente el modelo en busca de diferencias de desempeño entre grupos.
💡 Ejemplo: Un sistema de concesión de créditos basado en un modelo entrenado con datos históricos podría penalizar a grupos minoritarios por patrones heredados del pasado.
4.3.2. Privacidad y Cumplimiento Normativo
Marco legal: GDPR (Europa), CCPA (California), u otras leyes de protección de datos personales.
Buenas prácticas: Minimizar la recogida de datos (privacy by design). Asegurar la trazabilidad y el consentimiento informado del usuario.
4.3.3. Transparencia y Explicabilidad
Descripción: Modelos “caja negra” (ej. deep learning complejo) pueden generar desconfianza o incumplir requisitos legales en sectores como finanzas o salud.
Buenas prácticas: Herramientas de explicabilidad (SHAP, LIME). Políticas de AI explicable y responsable.
Checklist Ético
Revisión de variables sensibles o potencialmente discriminatorias.
Documentación de la procedencia de los datos (data lineage).
Cumplimiento legal y normativo (GDPR, HIPAA, etc.).
Plan de comunicación transparente a los stakeholders afectados.

CONCLUSIONES Y RECURSOS ADICIONALES
5.1. Resumen de los Beneficios de CRISP-DM
Estructura Clara
Establece un marco organizado, dividiendo el proyecto en fases: comprensión de negocio, comprensión de datos, preparación, modelado, evaluación y despliegue.
Facilita la comunicación y coordinación entre equipos técnicos y áreas de negocio.
Reducción de Riesgos
Al seguir un proceso estándar, disminuye la probabilidad de saltarse pasos críticos (p.ej., evaluación adecuada de la calidad de datos o definición clara de objetivos).
Permite identificar cuellos de botella y problemas potenciales de forma temprana.
Adaptabilidad
Aunque nació para minería de datos “tradicional”, se ajusta perfectamente a proyectos de Machine Learning, Deep Learning y Big Data.
Es agnóstico a la industria y puede combinarse con enfoques ágiles, MLOps y metodologías de gestión de proyectos (Scrum, Kanban, PMBOK).
Foco en el Negocio
Prioriza desde el inicio la comprensión de objetivos y métricas de negocio, garantizando que el proyecto genere valor tangible.
Ayuda a “aterrizar” la tecnología en un ROI concreto, lo que a su vez refuerza la adopción y el apoyo organizacional.
Escalabilidad y Ciclo de Vida
Contempla la fase de Despliegue y realimenta la necesidad de monitoreo y mejora continua.
Favorece la evolución del proyecto en ciclos iterativos, actualizando el modelo cuando cambian los datos o los objetivos del negocio.
5.2. Siguientes Pasos y Proyección a Futuro
Metodologías Combinadas
Integrar CRISP-DM con frameworks de MLOps (como MLflow, Kubeflow o Airflow) para asegurar un ciclo de vida robusto y automatizado de los modelos.
Adoptar prácticas de DevOps y DataOps, permitiendo entregas continuas, escalabilidad y colaboración transparente entre equipos.
Ética e IA Responsable
A medida que crece la capacidad de modelos de IA, es vital continuar revisando aspectos éticos, de privacidad y de explainable AI.
Impulsar políticas claras en la organización para evitar sesgos o usos indebidos de la tecnología.
Aplicaciones en Nuevos Dominios
Con la expansión de datos IoT, 5G y automatización de procesos, surgirán nuevos proyectos de analítica en áreas como vehículos autónomos, ciudades inteligentes, robótica avanzada.
CRISP-DM puede servir como base adaptable para estructuras más complejas de analítica en tiempo real (streaming data).
Formación Continua y Actualización
La ciencia de datos evoluciona rápido; los equipos deben mantenerse actualizados en nuevas librerías, metodologías y tendencias (AutoML, Transfer Learning, Large Language Models).
Fomentar el intercambio de conocimiento internamente (community of practice) y externamente (conferencias, webinars).
Construir una Cultura Data-Driven
Más allá de los proyectos puntuales, la adopción de una mentalidad de datos a nivel organizacional garantiza la sostenibilidad y el éxito de los esfuerzos analíticos.
Implicar a la alta dirección, definir estructuras de gobierno de datos y compartir los logros para incentivar la colaboración.
CRISP-DM es más que un simple esquema de pasos: es una guía conceptual que, bien aplicada, ofrece beneficios tangibles y estratégicos para empresas de cualquier tamaño e industria. Su fortaleza radica en la flexibilidad y en el énfasis de alinear la parte técnica con los objetivos de negocio.
5.3. Fuentes de Información, Lecturas Recomendadas y Cursos
Para profundizar en cada fase de CRISP-DM y en las tecnologías de ciencia de datos, recomendamos:
Ameisen, E. (2019). Building Machine Learning Powered Applications. O’Reilly Media.
Burkov, A. (2020). Machine Learning Engineering. True Positive Inc.
Chapman, P., Clinton, J., Kerber, R., Khabaza, T., Reinartz, T., Shearer, C., & Wirth, R. (2000). CRISP-DM 1.0: Step-by-step data mining guide. CRISP-DM Consortium. Recuperado de https://www.crisp-dm.org
CRISP-DM Consortium. (2000). CRISP-DM 1.0: Step-by-step data mining guide. Recuperado de https://www.crisp-dm.org
Data Quality Campaign. (s.f.). Recursos sobre calidad y gobernanza de datos. Recuperado de https://dataqualitycampaign.org
Data Science Central. (s.f.). CRISP-DM methodology overview. Recuperado de https://www.datasciencecentral.com/profiles/blogs/crisp-dm-methodology-overview
Exploratory Data Analysis — John W. Tukey (Referencia clásica no siempre disponible en línea; si se desea una cita formal, consultar versión impresa u otro repositorio académico.)
Fawcett, T., & Provost, F. (2013). Data Science for Business: What You Need to Know about Data Mining and Data-Analytic Thinking. O’Reilly Media.
Gerón, A. (2022). Hands-On Machine Learning with Scikit-Learn, Keras & TensorFlow (2da ed.). O’Reilly Media.
Google. (s.f.). Responsible AI Practices. Recuperado de https://ai.google/responsibilities/responsible-ai-practices/
Han, J., Pei, J., & Kamber, M. (2011). Data mining: Concepts and techniques (3ra ed.). Elsevier.
Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning: Data Mining, Inference, and Prediction (2da ed.). Springer.
IBM. (s.f.). Analytics solutions unified methodology (ASUM-DM). Recuperado de https://www.ibm.com/support/knowledgecenter
IBM. (s.f.). Conceptos básicos de ayuda de CRISP-DM. Recuperado de https://www.ibm.com/docs/es/spss-modeler/saas?topic=dm-crisp-help-overview
KDnuggets. (s.f.). CRISP-DM, still the top methodology for analytics, data mining, or data science projects. Recuperado de https://www.kdnuggets.com/2016/03/crisp-dm-top-methodology-analytics-data-mining-data-science-projects.html
Knowledge Discovery in Databases (KDD). (s.f.). Portal oficial. Recuperado de http://www.kdd.org/
Kuhn, M., & Johnson, K. (2019). Feature Engineering and Selection: A Practical Approach for Predictive Models. Chapman & Hall/CRC.
Microsoft. (s.f.). Team Data Science Process (TDSP) — Microsoft Docs. Recuperado de https://docs.microsoft.com/en-us/azure/machine-learning/team-data-science-process/overview
Molnar, C. (2019). Interpretable Machine Learning. Recuperado de https://christophm.github.io/interpretable-ml-book/
Project Management Institute (PMI). (2021). A Guide to the Project Management Body of Knowledge (PMBOK® Guide) (7ma ed.). PMI.
Shmueli, G., Bruce, P. C., Yahav, I., Patel, N. R., & Lichtendahl, K. C. (2017). Data Mining for Business Analytics: Concepts, Techniques, and Applications in R. Wiley.
Store de Oscar Schmitz. (s.f.). Workshops y formaciones sobre adopción de IA y despliegue en entornos empresariales. Recuperado de https://store.oscarschmitz.com
The Open Guide to Data Engineering. (s.f.). Sección de ingesta y exploración de datos. Recuperado de http://www.dataengbook.com/
VanderPlas, J. (2016). Python Data Science Handbook. O’Reilly Media.
Wirth, R., & Hipp, J. (2000). CRISP-DM: Towards a standard process model for data mining. En Proceedings of the 4th International Conference on the Practical Applications of Knowledge Discovery and Data Mining.
Witten, I., Frank, E., & Hall, M. (2011). Data Mining: Practical Machine Learning Tools and Techniques (3ra ed.). Elsevier.
Sigamos inspirando al mundo
Tu opinión es clave en esta aventura de conocimiento y transformación. ¿Qué ha parecido los contenidos de hoy? ¿Hay algún tema sobre el que te gustaría aprender más o alguna tendencia que crees que deberíamos explorar juntos?
Comparte tus ideas y sugerencias. Juntos, seguiremos inspirando, compartiendo y aprendiendo, transformando lo imposible en posible.
💪 Conoce más sobre nuestros contenidos digitales 🚀
❓ Contáctame a través de este formulario.
💙 Desde hace años, me dedico a escribir y compartir contenido que impulsa la transformación de líderes empresariales como tú, hacia un futuro mejor. Este newsletter, que es gratuito, no es barato de producir. Dedico cientos de horas y recursos cada semana para asegurarme de ofrecerte el mejor contenido posible.
💪 Tu apoyo como miembro exclusivo es fundamental para mantener este proyecto vivo. Por el costo de un café, puedes contribuir a que este trabajo siga siendo accesible para todos. Si lo que hago ha enriquecido tu vida o te ha brindado nuevas perspectivas, considera unirte como miembro exclusivo a MartesCoach.
💰 No hay monto mínimo: tú decides cuánto vale mi trabajo y los beneficios son los mismos para todos los suscriptores. Puedes sumarte, desde cualquier lugar del mundo.
🚀 Tu contribución es crucial para que este contenido siga siendo gratuito y accesible. Gracias por creer en mi trabajo y por ayudarme a seguir inspirando y educando a transformar más líderes hacia un futuro mejor.